In my previous post
Data-Shining in Glimmer, I introduced one method of data-binding following this syntax:
[widget, :widget_property] <=> [model, :model_property]
In this post, I will talk about another way to do data-binding, which may feel more natural to some programmers and offer some advantages over the syntax above.
To avoid confusion, I will dub the data-binding mini-DSL shown above
Shine, and I will call the syntax that I am about to demonstrate
Glimmer's built-in data-binding syntax.Here is a Login window example following the Model-View-Presenter pattern:
class LoginPresenter
attr_accessor :user_name
attr_accessor :password
attr_accessor :logged_out
def initialize
@user_name = ""
@password = ""
@logged_out = true
end
def login
self.user_name = ""
self.password = ""
self.logged_out = false
end
end
login_presenter = LoginPresenter.new
login_shell = shell {
text "Login"
composite {
layout GridLayout.new(2, false)
label { text "Username:" }
text {
text bind(login_presenter, :user_name)
enabled bind(login_presenter, :logged_out)
}
label { text "Password:" }
text(SWT::PASSWORD | SWT::BORDER) {
text bind(login_presenter, :password)
enabled bind(login_presenter, :logged_out)
}
button {
text "Login"
enabled bind(login_presenter, :logged_out)
on_widget_selected { login_presenter.login }
}
}
}
login_shell.open
Here is a screenshot of the UI before logging in:
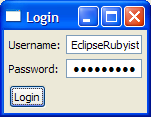
Here is a screenshot of the UI after loggin in:
.PNG)
As you can see, the LoginPresenter abstracts all of the presentation logic in a model, containing the username, password, and logged_in attributes. The view, written with Glimmer's syntax, is data-bound to the presenter.
For example, "text bind(login_presenter, :user_name)" indicates that the text of the username textbox on the screen is data-bound to the user_name property on the login_presenter model. When the user enters text into the text box, it gets automatically stored in the model. Later, when pressing the Login button, the listener fires the model login method, which has access to all the data the user entered, and can do all the work within the model.
Another example is "enabled bind(login_presenter, :logged_out)" on the Login button, which binds the enablement of the button to whether the user is logged in or not.
What is so nice about data-binding in general is that you can test-drive presentation logic easily without dependencies on the widgets and without any awareness of how information is visually layed out on the screen, so layout can vary independently.
Here is how to data-bind following the Shine mini-DSL introduced in my
last post about Glimmer:
login_shell = shell {
text "Login"
composite {
layout GridLayout.new(2, false)
label { text "Username:" }
@username_text = text { }
label { text "Password:" }
@password_text = text(SWT::PASSWORD | SWT::BORDER) { }
@login_button = button {
text "Login"
on_widget_selected { login_presenter.login }
}
}
}
| [@username_text, :text] | <=> | [@login_presenter, :user_name] |
| [@username_text, :enabled] | <=> | [@login_presenter, :logged_out] |
| [@password_text, :text] | <=> | [@login_presenter, :password] |
| [@password_text, :enabled] | <=> | [@login_presenter, :logged_out] |
| [@login_button, :enabled] | <=> | [@login_presenter, :logged_out] |
login_shell.open
Which method to use?
While this largely depends on personal preference, there are a few potential trade-offs.
Here are the advantages that Shine offers over Glimmer's built-in data-binding syntax:
View syntax is focused on layout concerns only
Having the data-binding logic decoupled from the view allows you to reuse the same view with different data-binding scenariosHere are the advantages that Glimmer's built-in data-binding syntax offers over Shine:
May be easier for some to think about and define data-binding while in the process of laying out widgets
Having data-binding code mixed in with widget declarations makes it easier to later spot and maintain data-bindings for the widgets they are tied toIn either case, data-binding greatly facilitates following the MVP architectural pattern to write easy-to-maintain testable code for desktop applications.
Stay tuned for more on how to benefit from the MVP pattern when building SWT applications with Glimmer.

.PNG)
